一个强化学习算法包括以下几个部分:Model、Policy、Value Function。对于Model,如果是马尔科夫决策过程(MDP),一般包括状态转移的概率模型,以及一个Reward Model,也就是奖励的模型。其实不难理解,既然涉及到马尔科夫链,那一般就有转移概率矩阵;另外这是决策模型,每次决策对应有奖励,所以还有一个奖励模型。另外,马尔科夫链的转移概率也会涉及到决策,比如:

其中s_t是当前状态,s是state的意思,a_t是当前的决策,a是action的意思,它的意思就是一个条件概率,如果当前状态是s,当前决策是a,那么下一次状态到s'的概率是多少呢?就是这个条件概率。
另外,做了这个决策,还要获得相关的奖励,也就是reward,那么应该是多少呢?本质上是一个条件期望:
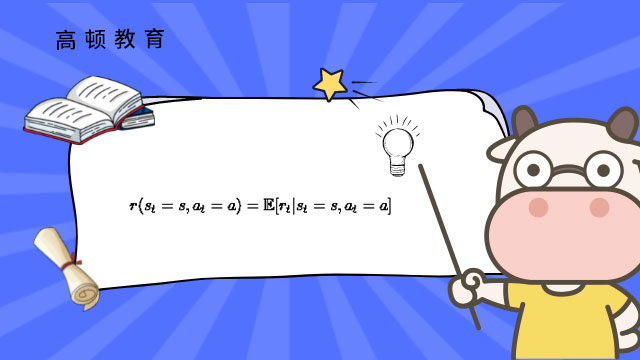
它的意思也很显然,就是当前状态是s,当前决策是a的情况下,当前的reward(假设为r_t)的期望是多少的意思。
为什么要用到期望呢?因为有时候这个奖励具有随机性。
例如现在的状态是高三了,可以选择出国,可以选则参加高考;如果选择出国,这是action,但对应的结果也是随机的,可能申请到这所学校,可能申请到那所学校;比如申请到前10的概率是10%,申请到前50的概率是50%,或许最终的期望就是申请到第50名左右的学校。因此,不是说做了决策结果就是确定的。
最后一个是Policy,这是比较重要的概念,它的意思可以理解为策略,就是面对当前的状态,应该如何做决策?
因此,一个policy,可以理解为从状态到决策的一个映射。
比如状态的集合记为S,决策(或者说动作)的集合记为A,那么policy就是一个S->A的映射。
Poliyc有确定性的,也有随机的。
确定性的Policy很好理解,就是面对一个特定的状态s,对应有一个确定的决策a。
随机的Policy意思是对于一个特定的状态s,对应的是一个决策的分布。此时可能是这个action,可能是那个action,不是确定的。
比如下棋,面对同样的棋局,可能有几个备选的方案,每次选哪个是随机的,不是确定的。
应该说,强化学习研究的问题大部分都是随机性的policy。

最后一个重要的概念是value function,这个会比较绕一些。
一个value function一定跟一个policy有关,或者说是关于这个policy的value function。
比如一个value function设为V,当前状态假设为s,它计算的是在一定的policy下,未来可以获得的收益的折现求和之后的期望值。
可以看出比较绕,因为它涉及到了很多的随机性。
比如对当前状态s_t=s,未来可以采取的决策是多种多样的,每种决策对应的结果也是随机的。比如随机的policy,对于这种状态s,它可以采取的action是随机的;每个action下,得到的收益也是随机的。这两重随机性要考虑。
还有就是折现值,这涉及到一个折现率discount ratio。为什么需要这个折现率呢?如果从金钱的角度,货币有时间价值,现在的100块钱,跟一年之后的100块钱,肯定不一样;一年之后的100块钱折现到现在要有一个折现率。一般来说,如果利率是r,折现率就是1/(1+r),所以,一般折现率是大于零小于1的,特殊情况可以取等号。
如果折现率是0,也就是未来收益不管多少都不算,只算当前收益;
如果折现率是1,也就是未来收益统统都算,而且不需要衰减。
强化学习一般用于玩游戏,会希望不要做一些无用功。比如理论上一个小人可以左走一步右走一步,拖延时间,就是不去打怪兽,也不去吃果子。但如果有折现率,现在吃果子有100分,但拖到几步之后吃果子只有90分,会迫使机器不会故意拖延时间。
当然,折现率设置不好,也会影响结果。比如下围棋,如果折现率接近1,可能会放着棋子就是不去吃,错失良机;如果接近0,可能会类似贪心算法,很快就吃,否则未来吃分数就不高;因此,本质上也是调参玄学。
好了,上面介绍了RL的3个组成部分:model,policy,value function,然后可以分成两大类:model-based和model-freee。
model-based的意思就是会清楚知道模型,包括马尔科夫决策模型,奖励模型等,都会给出来;但可能并不知道policy或value function。
model-free的意思就是连模型都没有,至于policy和value function,可能知道可能不知道。
比如俄罗斯方块,其实就4种积木,每种1/4,状态就是当前的盘面形态,因此状态转移概率矩阵是知道的,奖励模型也是知道的,这就是model-based,但我们并没有policy,事实上我们的任务就是要设计policy来玩。policy都没有,那么value function肯定也没有的。
但绝大多数时候是没有这么明确的状态转移概率的。比如下围棋,状态转移i概率跟决策有关的,但肯定不知道对手如何决策,甚至决策的概率分布也不知道。这个不是随机的。
俄罗斯方块的概率分布是确定的,因为4种方块每个出来的概率都是25%;但对于棋局,每个格子下的概率不是一样的,可能这个高,可能那个高,不知道的。这种情况下一般可以蒙特卡洛模拟,比如AlphaGo用的蒙特卡洛搜索树。
当然,也可能不知道model,但知道policy的。比如现在高三,下一步读大学,我不知道能去哪一所大学,这个概率不知道的;但我的policy是知道的,只能申请啊,只是不知道能申到哪一所。
当然,哪怕model-based,也是需要蒙特卡罗模拟的。哪怕知道了状态转移的概率,也要按照这个概率不断生成随机样本来研究。