


一般学机器学习的都知道有个定理,就是说整体误差Mean Square Error(MSE)包括了Bias(偏差)和Variance(方差)两个部分,如果参数越来越多,那么Bias会越小,而Variance会越大。道理也很简单,因为参数越多,越容易拟合真实的向量,但每个参数的估计都带来一点随机性,整体方差当然就大了。
一般的最小二乘是无偏估计,为了降低方差,提高泛化能力,一般会牺牲精度,比如各种正则化方法都可以降低方差,但都会引入Bias。
但所有以上这些,都是在低维统计众的结论,也就是默认参数的个数p小于样本的数量n。
但到了高维统计,也就是p>n甚至p>>n的时候,也就是p远大于n的时候,以上结论有时候并不成立。
就好像牛顿力学,只在低速宏观物体运动中成立,但在高速微观运动中并不成立。机器学习、统计学其实跟统计物理有类似的地方。
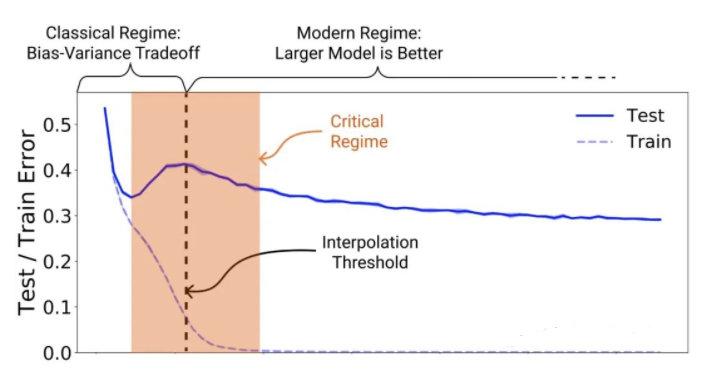
比如现在的机器学习中有个词叫做double descent,也就是所谓“双重下降”,指的测试误差随着参数个数的增加,一开始先下降,然后上升,这是传统机器学习的情况;但到了高维机器学习,某些情况下,随着参数的增加,它还会继续下降。
比如这是一幅比较经典的double descent的图:
还有一些简化实验的图
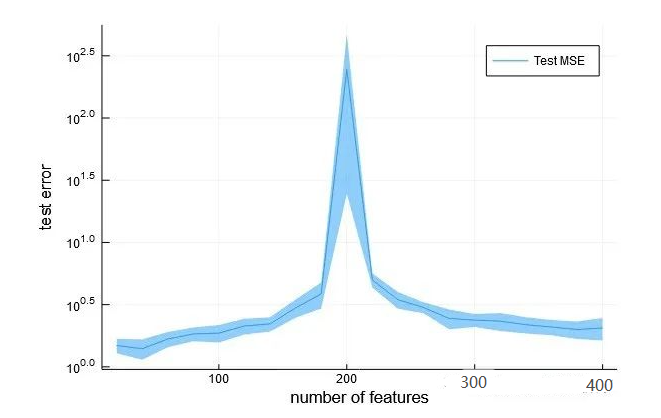
都可以看到,随着features(特征)的数目逐渐增加,测试误差先下降,然后增加,最后继续下降。
这个就具有很强大的现实意义,意味着人们不用担心训练集过度优化,不用担心大力出奇迹,不用担心过度拟合,只要成本可以支持,比如超级计算机够强大,内存足够大,完全可以拟合超级复杂的模型,参数越多越好,反正最后测试集误差也是会下降的。
主要的原因在于,比如p>>n,这里n=200,如果p=400,也就是特征数目是400,远大于样本数量。进一步假设,其中只有200个特征是有意义的,其它都是噪音;那么噪声变量越多,有意义的那部分特征只是一个更小的子空间,预测将越来越不准确,bias会越大,因为预测会越来越不准确;但同时,由于噪声多了,如果加入一定的正则化条件,那么分配给每个特征的系数绝对值会更小,也就是variance会更小,反而不容易过度拟合。
比如我找一篇雄文来说明一下,美国统计学总统奖得主、斯坦福统计系的大佬、统计学习圣经Elements of Statistical Learning的作者Tibshirani,他儿子小Tibshirani在一篇论文是这么写的:
看来美国也是阶层固化啊,统计学大佬的儿子继续搞统计,说不定未来也拿总统奖。学术垄断,世风日下。
回到正题,反正也说明我说的没错,还真有这事。因此,继续可以得到一些反直觉的结论:
- 数据不要太多。比如有200个特征,如果用1000个数据,那么是p>n,普通的低维统计;但如果用100个数据,就是p>n,变成高维统计了,高维统计就不怕过度拟合了。
- 可以尽情使用更多的参数和更复杂的模型。因为貌似大佬说最后测试误差还是会下降的,那么只要参数越来越多,大力出奇迹就可以的。
- double descent不是深度学习特有。
上面例子可以看出,普通的线性回归也会有这样的特性,所以也不要太迷信深度学习。结构太复杂,反而掩盖了事情的本质。
最后简单用R语言做一个实验来验证一下:
random_features <- function(n=100, d=100, num_informative_features=20) {y <- rnorm(n)X <- matrix(rnorm(n*min(d, num_informative_features)), nrow=n) + yif (d>num_informative_features)X <- cbind(X, matrix(rnorm(n*(d-num_informative_features)), nrow=n))return (list(X=X,y=y))library(lmeVarComp)set.seed(200)n <- 200ds <- seq(from=20, to=2*n, by=20)[-10]num_informative_features <- 1000nreps <- 10mses <- matrix(0, nrow=length(ds), nreps)train_errors <- matrix(0, nrow=length(ds), nreps)for (rep in 1:nreps) {mse <- c()train_error <- c()for (d in ds) {aa <- random_features(n,d,num_informative_features)Xtrain <- aa$Xytrain <- aa$yw <- mnls(Xtrain, ytrain)bb <- random_features(round(n/10),d,num_informative_features)Xtest <- bb$Xytest <- bb$ymse <- c(mse, sum((ytest-Xtest%*%w)^2))train_error <- sum((ytrain-Xtrain%*%w)^2)}mses[,rep] <- msetrain_errors[,rep] <- train_error}mean_mse <- apply(mses, 1, mean)plot(ds,mean_mse, type="l")
最后上图:
很明显看到了double descent,测试误差先下降后上升,在p=n会爆炸,这里图删除了那个点,否则会压缩的太厉害;然后p>n之后又继续下降了。
另外还可以看到训练集的误差是零,高维统计一般可以在训练集做到完美拟合:
mean_te <- apply(train_errors, 1, mean)plot(mean_te, type="l")
值得注意的是,这里求解使用了minimum norm least squres(mnls),这个不同于lasso,ridge和least squares,需要用到专门的包求解。由于p>n,普通的最小二乘无法求解,如果是lasso、ridge,似乎没有类似的效果。不清楚python有没有类似的包,Julia会更方便,直接就行。
对于量化交易的启示也类似,如果不怕过度拟合,那么建模是很容易的事情。当然,交易有风险,入行需谨慎,我也只是抛砖引玉。

























